Migrating BBM Android Continuous Integration to Cloud with Genymotion Cloud and GCP — Part 1

This article is the first of a series of 3, which outlines what Continuous Integration is, why we are doing it, how we did it in the first place, and what problems we encountered with our initial design. The others will describe in detail all problems we faced, how we’re planning a solution for each problem, and how we’re implementing it.
KMK and BBM
In June 2016, KMK Online formed a global partnership with BlackBerry that allows KMK to develop BBM services for Android, iOS, and Windows phone platform.
BBM has gone through a significant re-engineering since then. One of the most notable feats is the successful live migration of millions of BBM users and its infrastructure, from North America to East Asia, without any noticeable service disruptions. It all happened while hundreds of engineers were building new features and re-engineering every part of the services.
From my point of view, it was all possible because of collective team effort, talented and dedicated team that work together, and supported by engineering practices that empower everyone to do their parts.
eXtreme Programming — Feedback

One of the most important engineering practices in KMK is the exercise of eXtreme Programming. As some of you might have known, there are five values in eXtreme Programming:
- Communication
- Simplicity
- Feedback
- Courage
- Respect
This article, however, focuses on getting Feedback. Specifically, getting feedback on integrating dozens of code changes to the repository, done by dozens of engineers working on BBM for Android.
When we started making changes to BBM, there were no sufficient automated tests that cover all parts of the functionality provided by the app. Almost everyone who touches the code base for the first time is afraid to make changes. It’s because there was no safety net to make changes. Having a safety net helps engineers to verify that their code changes do not break existing functionalities.
The most logical action to take on the problem is, well, to build the safety net ourselves. All team starts excavating the huge code base, analyzing what could we do, and including all the necessary tooling and libraries to build a bunch of test cases for various features available in the app. With all of these test cases in place, engineers can get feedback quicker, if their changes break existing test or not.
Continuous Integration
With contribution from all team, by the end of January 2017, we had our first Continuous Integration (CI) infrastructure set up in place, up and about, running automated tests written using Espresso, for every code changes that were put in by all team. But, what is Continuous Integration exactly?
Continuous Integration is a development practice that requires developers to integrate code into a shared repository several times a day. Each check-in is then verified by an automated build, allowing teams to detect problems early.`
What our first CI infrastucture looked like? Below is an illustration of how we structured it.
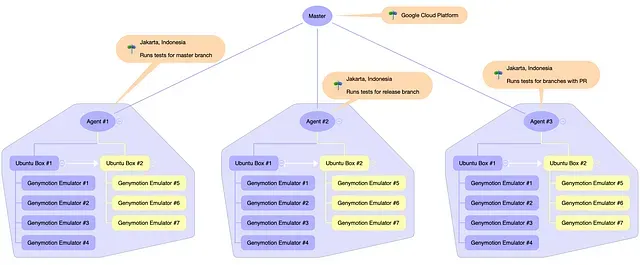
The master node, runs on Google Cloud Platform, has 3 agent nodes attached to it. The agent nodes are running at our office in Jakarta, Indonesia.
As you can see, each agent is backed by two Ubuntu box, with each box hosts 4 and 3 Genymotion Desktop emulators. So, in total, each agent has 7 Genymotion emulators that can be used to run instrumentation tests.
Each agent has its role:
Agent #1runs tests formasterbranchAgent #2runs tests forreleasebranchAgent #3runs tests for branches associated with a pull request (PR)
There are quite a lot of things to do to set up the infrastructure properly:
Having done all that, we can run our CI process after connecting all dots, from GitHub to Jenkins, from Google Cloud network to our office network, and everything in between.
We also wrote a bunch of scripts to run and maintain our infrastructure, such as:
Problems

Months after running and maintaining our CI, we start noticing many problems. Problems we faces are as follow:
Those problems are slowing down the team, and reducing the productivity and delivery time. In the next article, I’m going to explain those problems and how we plan to overcome each of them.


