Migrate to Grafana Oncall

TL’DR
We are happy with OpsGenie. But to reduce our cost, we are migrating off from OpsGenie to Grafana oncall in just 4 months. Overall, we have a positive experience and feel happy with the decision. There are some obstacles that we need to plan around but all is good.
On a peaceful morning in mid-October 2023, I arrived at the office and started setting up my workspace for the day. Suddenly, our TPM (Technical Program Manager) approached me and asked me to prepare a testing environment for several open-source tools related to incident management. I was baffled and thought, "Hey, we're using OpsGenie, right? Why do you want to install these tools?" He replied, "Yes, we're now exploring possibilities to move away from OpsGenie." I asked, "Ah, when does the OpsGenie contract expire?" "February next year," he said. My response? "Oh… we only have 4 months??".
We are happy with our OpsGenie usage here, but then he explained that this was one of TPM's initiatives to reduce cost. They had already decreased the number of on-call engineers in OpsGenie because OpsGenie charges on a per-user basis. Now, they felt the need to move away from OpsGenie entirely due to potential further cost savings.
However, I had several concerns. For the alternative solution, we needed to consider integration with Google Chat, Datadog, and email-triggered alerts. Other crucial factors included the resilience aspect (after all, this is the very core of our incident response tools), its isolation from the rest of our infrastructure (imagine our incident response tools going down along with our user-facing services—very funny), and how to alert people during off-hours. Four months seemed like an incredibly tight timeline to execute such a migration. Moreover, the new tool had to be ready by early December. This would allow the TPM to present it to management for assessment, determining whether to proceed with this initiative or not. This meant we had only a month and a half to prepare the tool.
It was decided that I would lead the technical planning and implementation for this initiative. A Technical Program Manager (TPM) would assist me with configuring specific details, such as setting up the Datadog integration for our new tool and integrating with Google Chat, as well as lead the developer team onboarding process. Occasionally, I got help for the implementation side from colleagues. This allowed me to focus on planning aspects of the project.
Fortunately, the TPM had already been testing some tools that didn't fit our use case, such as LinkedIn's Iris and oncall. This allowed us to narrow down our alternatives quickly. As a happy Grafana dashboard user since 2019, I knew that Grafana had an open-source project called oncall (different oncall) for incident response tool. I proposed self-hosted Grafana oncall to the TPM, and they agreed to proceed with this option.

Day 0: Planning
Operational Planning
We listed all core features that we absolutely needed:
- Datadog Integration.
- Receive email-based alerts.
- Send notification to Google Chat.
- Send notification to on-call engineers outside working hours.
Receive Alerts from Datadog
Self-hosted Grafana oncall doesn't provide built-in Datadog integration. However, this isn't a problem. Datadog offers webhook integration, and Grafana oncall provides an endpoint to receive HTTP requests. Datadog can create a custom HTTP request body, allowing us to design a custom structure and include any information we want to send to Grafana oncall. Interestingly, Grafana oncall's integration includes JSON parsing to interpret the HTTP request body. This makes for a highly compatible and customizable integration.
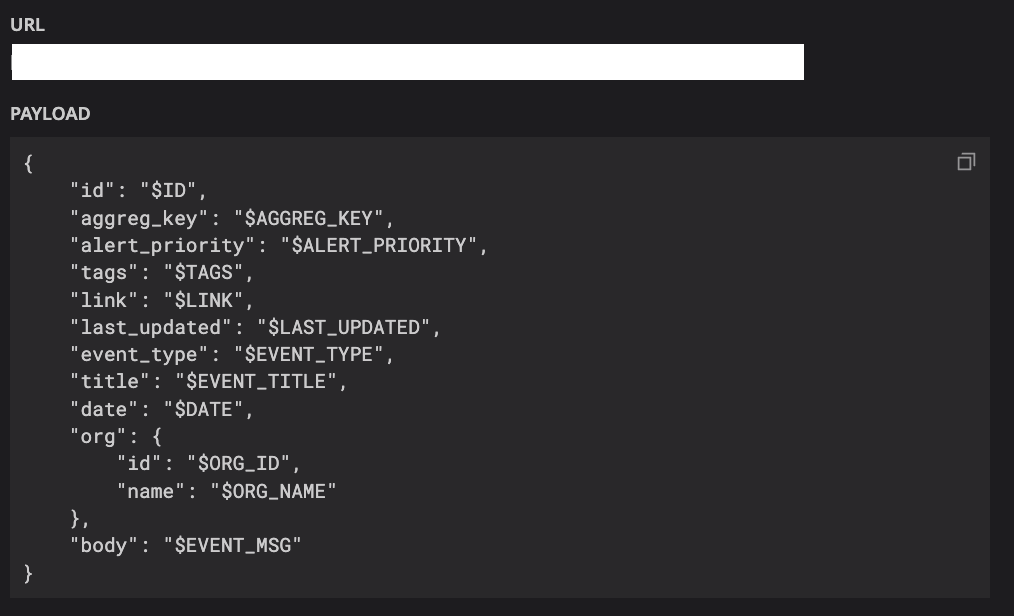

Receive Email-based Alerts
Grafana oncall provides a lot of email service provider integration such as AWS SES, Mailgun, Postmark, etc. We ended up choosing Postmark as our email service provider. We do have a problem with case-sensitive email addresses, but we could live with that.

Send Notification to Google Chat
While Grafana oncall does not provide built-in integration with Google Chat, Grafana oncall provide custom outgoing webhooks. We could create a workaround by creating outgoing webhook for each Google Chat webhook per space.
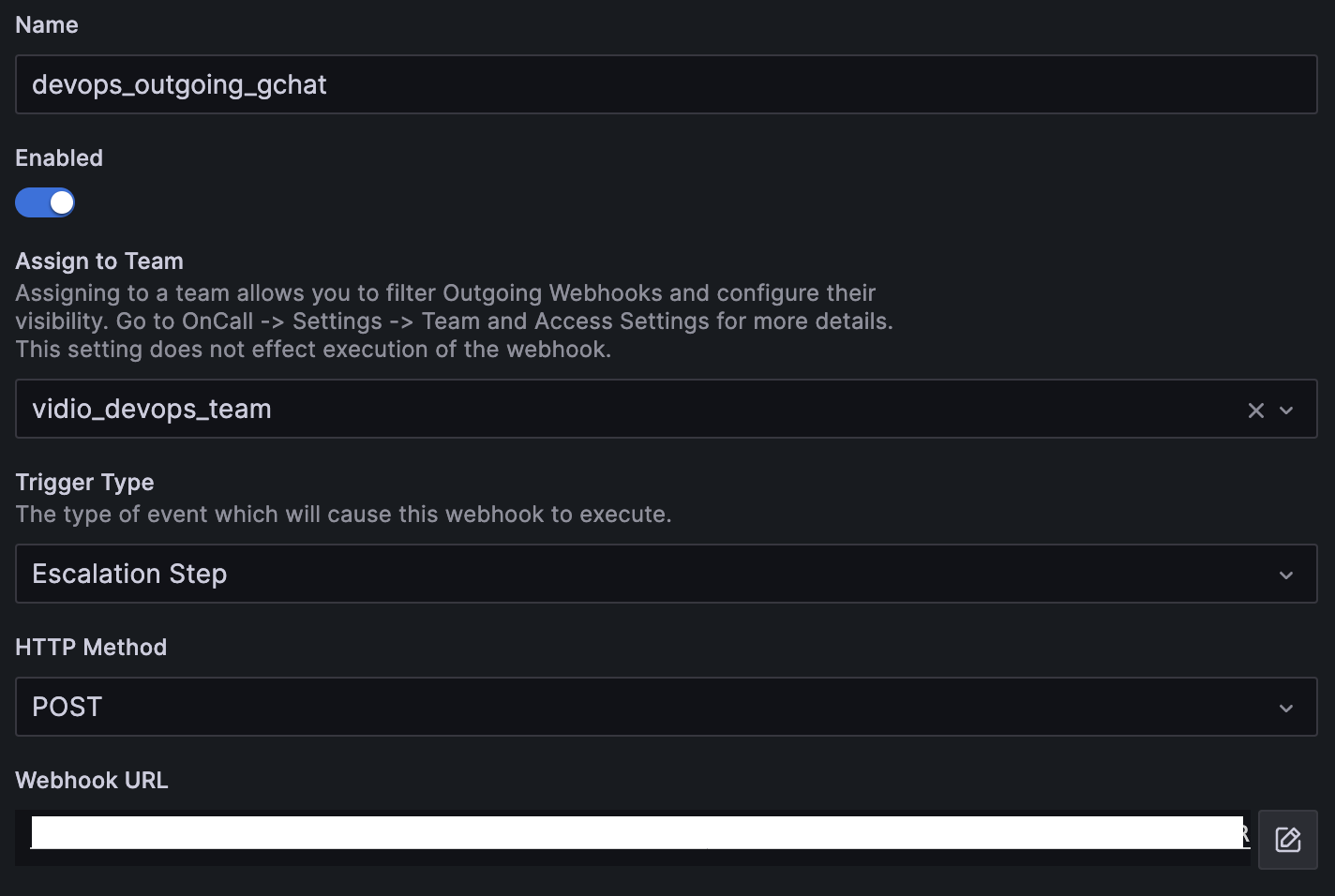
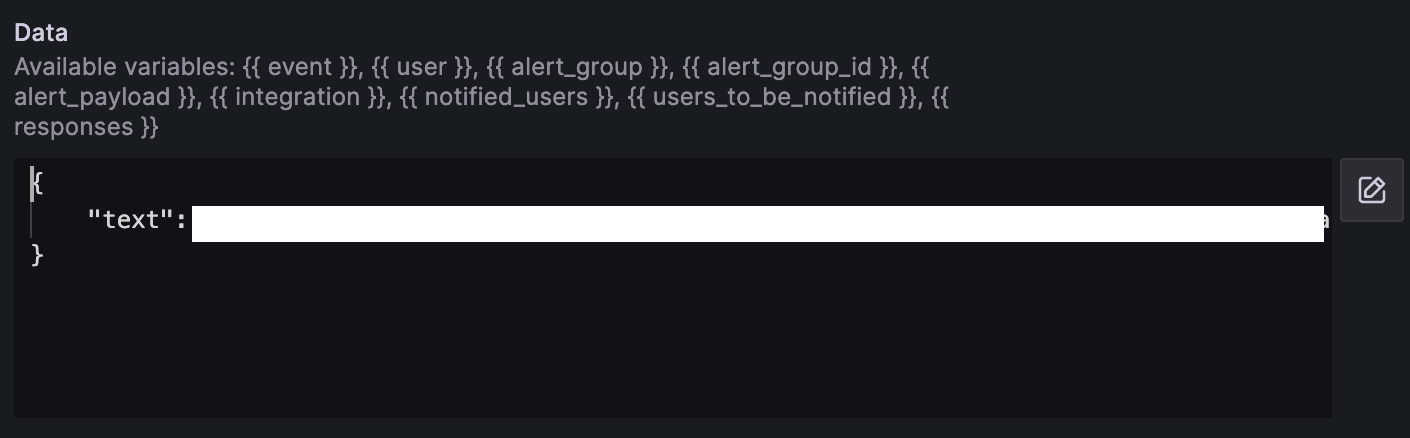
Send Notification to On-call Engineers Outside Working Hours
To my surprise, Grafana oncall has a mobile app that works similarly to the OpsGenie application. And it's available at both Play Store and App Store. And for P1 alerts that need immediate response, Grafana oncall also provides Twilio integration for calls and SMS.
At this point, we are really confident in how to operate Grafana oncall. It does not cover all our use cases with OpsGenie, but at least it covers all of our basic usage. I guide our TPM on how to create integration from Datadog to Grafana oncall and from Grafana oncall to Google Chat, also guide them on how to create schedules and escalation processes. I also asked them to try out the mobile apps and it turns out that they are satisfied with the apps.
While TPM is creating onboarding guides for the developer team and configuring webhooks and integration in Grafana oncall, now it's DevOps' turn to figure out how to make this Grafana oncall practically resilient and isolated.
Infrastructure Planning
We do expect that Grafana oncall would be a self-contained service so that we could treat it the same as you usually treat a status page service. No dependencies, isolated, easy to deploy, easy to maintain, maybe a SQLite for database. But alas, Grafana oncall require 4 dependencies: PostgreSQL, Celery, RabbitMQ, and Redis.
Note that we want to keep the maintenance needed for this Grafana oncall low while still maintaining reasonable isolation from our main infrastructure.
Looking at the dependencies, we planned to offload PostgreSQL and Redis to our trusty database SaaS vendor, Aiven. The cons here are that if Aiven goes down, Grafana oncall cannot access PostgreSQL and Redis that are hosted there.
For Celery and RabbitMQ, as we are using GKE and their official Helm Chart, we will use the Celery and RabbitMQ that come as the Helm Chart dependencies. Again, to keep the maintenance effort low.
For the isolation aspect, we settle with a different project, different GKE cluster, but still on the same network as our core business services. Why the same network? I don't know, somehow it never crossed my mind when I planned for this. I just realized that Grafana oncall is on the same network as our main infrastructure 2 months after the OpsGenie cut off. Now I'm just coping by thinking that maybe we don't have to isolate Grafana oncall that much.
We planned to set up a heartbeat sent from our local Grafana oncall to free tier Grafana oncall cloud. So that if there's something wrong with our Grafana oncall, we will still get notified.
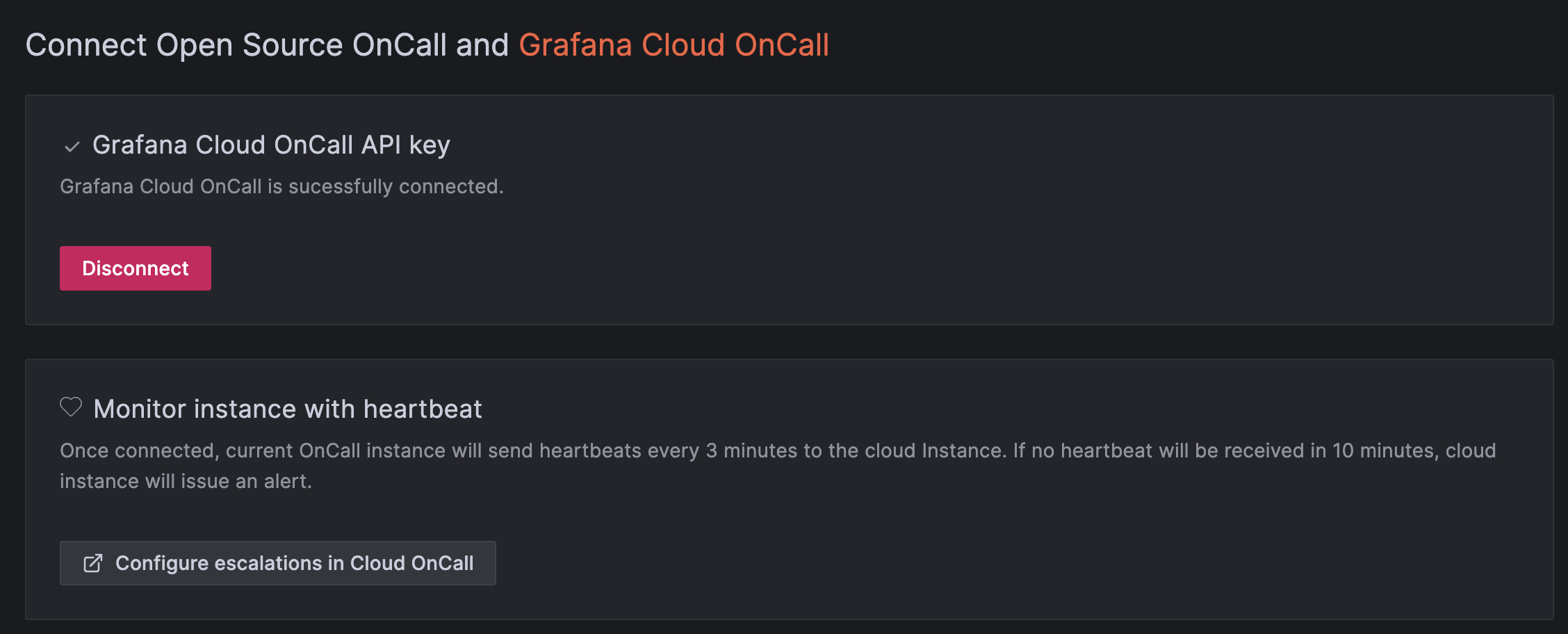
We feel like the infrastructure plan for Grafana oncall we have here is good enough. Considering how much time is left for us before the OpsGenie cut off, we could always improve it over time.
-26ea55.jpg)
Day 1: Deployment, Onboarding
We create a PostgreSQL database in Aiven, and then deploy our Grafana oncall via Helm Chart on a GKE cluster that is separated from our core service. After that we set up heartbeat to Grafana oncall cloud. There's no major incident in the deployment process.
The operational side from TPM and technical from DevOps side is done. All we have to do is to onboard the developer team to our new incident response tools.
Our TPM is quite exceptional in that they are able to plan and communicate to the developer team so thoroughly that the migration process is going quite smoothly. There are some minor dissatisfactions on the developer team side but we could resolve them peacefully.
One thing that I think is really crucial here is that TPM is diligently asking for feedback from the developer team, which allows us to quickly refine the onboarding process and optimize the Grafana oncall configuration as we go.
Day 2: Daily Operations, Maintenance
There's not much for our daily operational routine related to Grafana oncall, really. It's almost like Grafana oncall is a tool that you could deploy and forget.
I can't write a lot about the operational side of Grafana oncall, but it looks like the TPM team does not have any difficulty in managing Grafana oncall.
But for the infrastructure side, at least until the date that this blog is written (13 September 2024), we are only doing occasional Grafana oncall upgrades and we did not find any major difficulties. We even moved Grafana oncall from GKE standard cluster to GKE autopilot and the process was quite smooth.
Summary
At the beginning, we do face some challanges such as:
- A pretty tight timeline to work with.
- Self-hosted Grafana oncall didn't come with built-in Datadog and Google Chat integration.
- We needed to figure out how to keep our self-hosted Grafana oncall separate from our main services.
- We had to keep the maintenance costs down.
But now, looking back at our process when migrating from OpsGenie to Grafana oncall. We think we kind of overestimated the project difficulties. 4 months is indeed a short time to migrate a big and important service like OpsGenie, but it's actually really doable. Even with all the challanges that we get in the planning phase, we could finalize the migration plan in 1.5 months and it only took 1 week to deploy it.
Deployment wise, we think that the isolation and resiliency for Grafana oncall is enough. One thing that could make me sleep at night is that even though there's something wrong with our self-hosted Grafana oncall instance, at least we still get paged.
Few lessons that we learn from this migration (and maybe for you too, if you want to migrate to Grafana oncall):
- List all the features that you really need. This will serve as a preliminary assessment of whether migrating to Grafana oncall is viable or not.
- Be creative. But for this one, we are lucky that Grafana oncall's basic feature is flexible enough for us to create workarounds for features that aren't supported natively.
- Plan your infrastructure carefully. Decide how much isolation do you want for the Grafana oncall and how much engineering time that you want to allocate to maintain Grafana oncall.
- Gather feedback from your engineers diligently. After all, the ones who will use Grafana oncall are your Engineering Team.
Grafana oncall is so boring that I personally love it. Still low maintenance. No complaints from the developer team. No missing alerts. The best part is that no one is talking about our Grafana oncall. You know, "If there's no one talking about your things, it means that you are doing a good job".