Panduan Migrasi Services ke Kubernetes (Bagian 2)

Panduan ini berasal dari dokumentasi internal untuk tim engineering di Vidio, yang kami rasa mungkin berguna untuk dibagikan kepada komunitas yang lebih luas. Kami sadari ada background / context yang kurang lengkap yang kami masih belum sempat menambahkannya.
Setelah sebelumnya di Bagian 1 telah dijelaskan tentang komponen dan skill yang dibutuhkan untuk proses migrasi ke kubernetes, bagian ini akan menjelaskan proses migrasi service ke kubernetes, sebelum sampai production environment.
Workloads
Untuk menjalankan sebuah aplikasi di Kubernetes, kita menjalankannya di dalam sebuah Pod. Satu Pod bisa menjalankan lebih dari 1 container.
Kubernetes workloads resources adalah resources yang dikendalikan oleh controllers untuk me-manage pods. Contoh built-in workload resources di Kubernetes yaitu Deployment dan ReplicaSet, StatefulSet, DaemonSet, Job dan Cronjob.
Services pada umumnya menjalankan setidaknya satu workload. Contohnya, di sebuah Deployment, kita akan menentukan:
- Spesifikasi container:
- Image
- Command dan arguments
- Resource request dan limits: cpu, memory, ephemeral volume
- Environment variables
- Security context:
- User, group
- Volumes
Kita akan menulis sebuah file yaml yang berisi tentang sumber daya deployment. Contohnya:
Saat proses development kubernetes resources, kita mungkin perlu melakukan beberapa action seperti berikut:
Meng-expose aplikasi ke publik
Ingress
TODO: Ingress diimplementasikan oleh GKE melalui GCE menggunakan GCP Load Balancer
TODO: Pembuatan GCP LB membutuhkan waktu ~20 menit. Itulah sebabnya mengapa kami melakukan implementasi ingress melalui nakhoda. Jadi jika kami perlu menginstal ulang chart, sumber daya ingress tidak ikut dihapus.
API Gateway menggunakan Gloo Edge
Gloo Edge adalah sebuah API Gateway yang bisa berjalan di kubernetes. Di Vidio, Gloo Edge berjalan di antara Load Balancer dan application service.

TODO: Add picture
Ingress (GCP Load Balancer) -> Envoy (managed by Gloo) -> Application pods
Gloo Edge API Gateway menyediakan fitur-fitur penting seperti:
- Log akses HTTP yang seragam (unified)
Vidio memiliki beberapa application service yang ditulis dalam berbagai framework dan bahasa pemrograman. Access log yang dihasilkan pun berbeda-beda format. Di infrastruktur sebelumnya, kami menyesuaikan log akses nginx dengan format standar dan dicopy ke semua layanan, yang sebenarnya tidak diinginkan. Dengan API Gateway, log akses bisa diseragamkan tanpa ada duplikasi config.
- Metrik yang seragam
- Konfigurasi proxy yang standar
Daripada memiliki proxy yang berbeda untuk setiap application service (nginx, haproxy), API Gateway menyediakan konfigurasi standar untuk semua service.
Kemampuan ini digunakan oleh Flagger – canary engine yang digunakan untuk merilis aplikasi versi baru secara progresif.
- Delegasi Konfigurasi
Konfigurasi virtual service dan upstream menjadi tanggung jawab application developers, sedangkan Gloo dan envoy menjadi tanggung jawab DevOps engineers. Hal Ini bagus untuk produktivitas dan developer experience. Developers tidak perlu memikirkan maintenance Gloo.
Fitur-fitur di atas merupakan alasan utama kita menggunakan Gloo, dan yang terpenting adalah dukungan terhadap canary release melalui Flagger.
Arsitektur Gloo
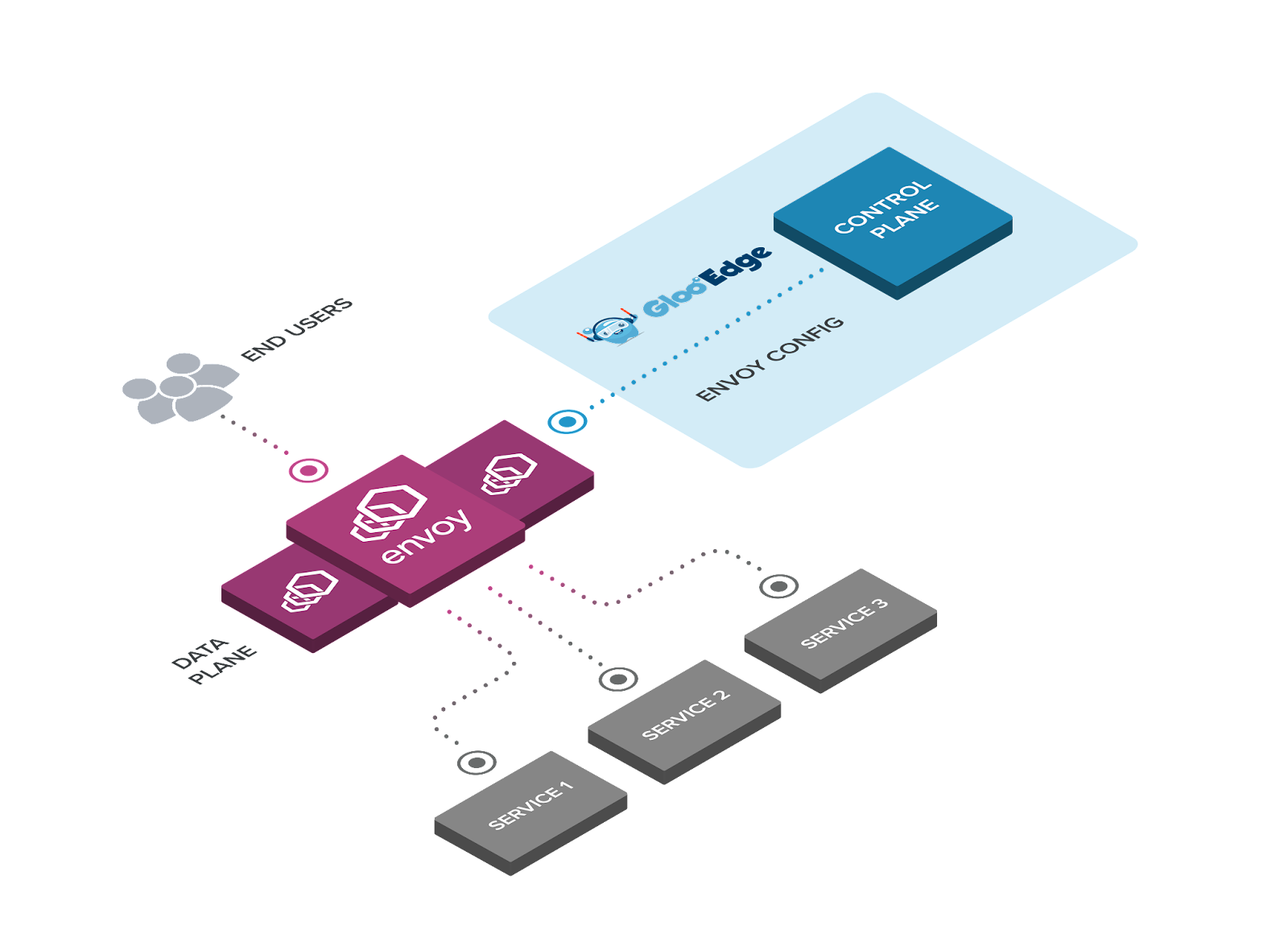
Konsep Penting yang perlu dipelajari:
Contoh dari services yang sudah berjalan:
- https://repo.kmklabs.com/kmk-online/nakhoda-charts/-/blob/master/hermes/templates/virtualservice.yaml
- https://repo.kmklabs.com/kmk-online/nakhoda-charts/-/blob/master/vidio-quiz/templates/virtualservice.yaml
CI/CD
CI (Continuous Integration)
Cakupan dari CI (continuous integration) di sini secara umum adalah:
- Menjalankan perintah-perintah otomatis untuk memastikan versi baru dari sebuah application service layak untuk di-deploy. Langkah-langkahnya biasanya berupa:
- Build software
- Compile source code, build assets, dan semisalnya
- Menjalankan automated tests
- Build container image
- Push container image
- Secara opsional men-deploy image yang dihasilkan ke environment staging
Contoh dari services yang sudah berjalan:
- https://rearci.build.kmklabs.com/job/hermes-build/
- https://repo.kmklabs.com/kmk-online/hermes/-/blob/master/scripts/jenkins/pipeline-ci-with-docker.groovy
CD (Continuous Delivery)
Seperti yang telah disebutkan di bagian sebelumnya, kami menggunakan GitOps untuk melakukan perubahan pada kubernetes cluster, termasuk men-deploy container image baru.
Jadi, jika kami ingin men-deploy image baru, kami hanya perlu meng-update repository (nakhoda, nakhoda-charts, atau keduanya). Lalu, GitOps engine (flux) akan meng-handle perubahannya ke dalam cluster.
Perlu dicatat bahwa terdapat setup helm release yang berbeda antara environment staging dan production. Di staging, kami biasanya ingin men-deploy versi terbaru dari nakhoda-charts untuk menerapkan continuous delivery. Jadi, di staging, kami biasanya mengarahkan helm source ke branch master. Dengan demikian, di staging kami dapat membuat perubahan, membuat commit baru terhadap perubahan tadi, kemudian melakukan git push ke repository. Selanjutnya, perubahan pada commit tersebut secara otomatis akan di-apply ke dalam kubernetes cluster.
Di production, kami ingin men-deploy versi yang sudah ditest di staging. Jadi, helm source-nya tidak diarahkan ke branch master. Sebaliknya, helm source diarahkan ke revisi/commit-id tertentu di nakhoda-chart yang telah ditest di staging. Jadi, jika kita ingin men-deploy pembaruan dari nakhoda-chart di production, kita hanya perlu memperbarui helm source yang relevan.
Harap diperhatikan bahwa ini hanya berlaku pada perubahan yang dilakukan di nakhoda-charts. Di dalam alur kerja sehari-hari, kita mungkin tidak perlu melakukan pembaruan nakhoda-charts. Jika kita hanya ingin men-deploy image baru, kita dapat mengekstrak image tersebut sebagai helm value dan menempatkan value tersebut pada Helm Release.
Canary Release
Masalah dengan Canary Release pada Infrastruktur berbasis VM
Sebelumnya pada infrastruktur berbasis VM (non Kubernetes), kami mengimplementasikan canary release dengan cara menyisipkan canary Instance Group pada GLB (Load Balancer) dan memberikannya traffic secara bertahap. Hal ini dilakukan oleh Ansible Playbook yang mengakses GLB secara langsung. Ada beberapa masalah terkait hal ini:
- Kompleksitas
Logic-nya cukup rumit. Ansible mungkin bukanlah abstraksi yang cocok untuk hal ini.
- Effort tinggi untuk di-reuse
Dibutuhkan effort lebih untuk bisa diimplementasikan di service lainnya.
- Tidak standar
Tweak yang digunakan bisa berbeda antara satu service dan service lainnya.
Di kubernetes, kami mengatasi masalah tersebut dengan menggunakan Flagger, sebuah canary engine yang menstandarisasi proses canary release di seluruh services.
Flagger
Manual Promotion Confirmation Dengan Release Portal
Flagger mendukung manual gating melalui webhooks. Untuk merespon webhook ini, dibutuhkan sebuah service. Sehingga kami membuat ReleasePortal yang akan merespon webhook flagger dan menyajikan antarmuka web untuk menyetel toggle manual gate.
Membuka tampilan release portal:
Pilihlah salah satu namespace yang memiliki canary, contohnya: Vidio Quiz. Kita akan melihat tombol switch pada kolom Confirm Promotion. Open berarti Flagger akan terus lanjut mempromosikan revisi baru.
Lebih detailnya, Release Portal bekerja dengan cara menyimpan toggle state (on/off) ke dalam storage. Di environment local development, release portal secara default menggunakan in-process memory. Di staging dan prod, release portal menggunakan redis. Kemudian, ketika Flagger memanggil webhook, Release Portal cukup memanggil state dari storage dan meresponnya.
Contoh dari services yang ada
- https://repo.kmklabs.com/kmk-online/nakhoda-charts/-/blob/master/hermes/templates/canary.yaml
- https://repo.kmklabs.com/kmk-online/nakhoda-charts/-/blob/master/vidio-chat/templates/canary.yaml
Autoscaling
Di Kubernetes, HorizontalPodAutoscaler memperbarui workload resource secara otomatis (seperti Deployment atau StatefulSet), dengan tujuan agar workload bisa di-scale secara otomatis sesuai dengan kebutuhan. Biasanya HPA dibuat untuk keperluan deployment, dengan mengkonfigurasi target utilisasi CPU pada parameter targetAverageUtilization.
Perlu diketahui bahwa agar HPA mampu menghitung persentase utilisasi komputasi, kita perlu menentukan resource request (CPU / memory).
Ada behavior lain saat HPA digunakan dengan Flagger (canary). Flagger akan menyalin konfigurasi deployment ke tempat yang baru dengan akhiran -primary. Deployment dengan akhiran -primary inilah yang akan melayani live traffic. Saat kita ingin membuat HPA, kita perlu menyiapkan dua HPA:
- Satu untuk canary deployment, sehingga pod canary dapat scale ketika berada dalam fase canary analysis / deployment. Hal ini ditujukan untuk mencegah adanya canary overload saat deployment berjalan pada high traffic.
- Satu untuk primary deployment
Contoh dari services yang sudah berjalan:
Logging
Arsitektur Logging Kubernetes
https://kubernetes.io/docs/concepts/cluster-administration/logging/
Kami menerapkan arsitektur berikut ini di cluster Kubernetes:
https://kubernetes.io/docs/concepts/cluster-administration/logging/#using-a-node-logging-agent
Kami menggunakan ElasticSearch untuk menyimpan dan mengindeks logs.
TODO: gambar architecture
Meng-query Logs
- Buka Kibana
- Pilih index pattern:

- Pilih Filebeat-* untuk logs dari Kubernetes
- Pilih logstash-json-* untuk logs dari VMs
Log records yang berada pada patterns filebeat-* dilengkapi dengan Kubernetes context sehingga memudahkan kita untuk melakukan filter berdasarkan namespace, pod, atau node.
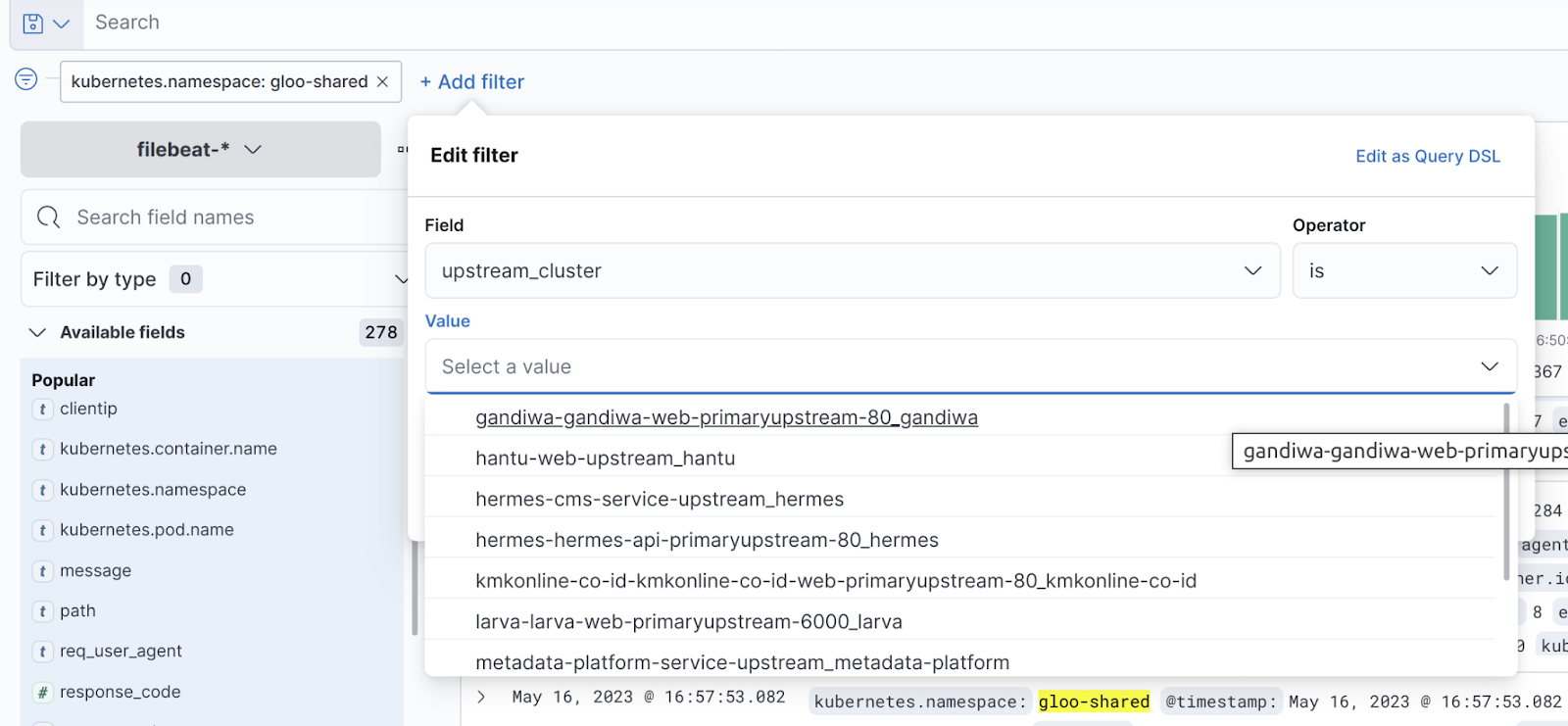
Seperti yang disebutkan sebelumnya di bagian API Gateway, salah satu manfaat yang kita peroleh dari API Gateway adalah access logs yang seragam. Dalam setup ini, kami dapat meng-query access logs dengan cara menerapkan filter berikut:
- kubernetes.namespace: gloo-shared
- upstream_cluster: service yang diinginkan
Monitoring
Kami menggunakan tool yang sama, Datadog, untuk memantau kubernetes. Perbedaannya terletak pada metrik. Basic metric yang kami pantau adalah utilisasi memori dan CPU pod, bukan memori dan CPU node.
Contoh dari services yang sudah berjalan:
- Dashboard: https://app.datadoghq.com/dashboard/dbg-jq5-y94/prod-vidio-chat-gke-details
- Monitor: https://repo.kmklabs.com/kmk-online/structura/-/blob/master/inventories/datadog/prod/vidio-chat/datadog_monitor.yaml
Keamanan
Network Policies dan Firewalls digunakan untuk ruang lingkup yang berbeda. Firewall digunakan pada tingkat VPC, menargetkan VM network tags. Sedangkan network policies digunakan pada kubernetes cluster yang menargetkan pods dan namespaces.
Lihat https://kubernetes.io/docs/concepts/services-networking/network-policies/
Contoh dari services yang sudah berjalan:
Di artikel berikutnya kita akan membahas proses production readiness dan rollout process.


