Important Things before Build a Machine Learning
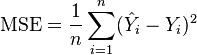
Sekarang ini Machine Learning sedang hype banget. Ditambah lagi dengan beberapa perusahaan teknologi raksasa seperti Facebook, Google, Twitter mengimplementasi machine learning pada productnya. Seperti News Feed Facebook, You might like this Twitter, atau Google deepmind dan search nya, serta Movie Recommendation di Netflix. Tentu ini sangat berguna sekali karena teknologi machine learning sangat membantu pengguna dan memudahkan pengguna dalam menggunakan sebuah produk. Untuk itu perusahaan, developer, konsultan pun mulai ingin mengimplentasi machine learning ke dalam produk mereka. Akan tetapi beberapa orang saat ingin mengimplementasi langsung sibuk dengan mengurusi stack seperti hadoop atau spark, hive, atau sibuk memilih algoritma apa yang akan digunakan dalam memodel datanya. Padahal, machine learning ini ibaratnya kita melakukan sebuah penelitian dan dimana dalam melakukan sebuah penelitian ada beberapa hal yang harus dilakukan sebelum menentukan penelitian itu. Yaitu metric yang cukup jelas dalam menentukan apakah sebuah penelitian itu berhasil.
Dalam implementasi kita juga harus menentukan metric apaa saja yang menentukan jika machine learning yang kita buat itu bekerja dengan baik. Ada 3 metric yang dapat kita gunakan yaitu :
1. Mean Square Error
Mean square error adalah jumlah rata selisih kuadrat antara actual dan prediksi
contoh :
actual = [1,1,1,1,1,1]
prediction = [1, 1, 1, 1]
mse = 1/5 (0 + 0 + 0 + 0 + 0) = 0 * 100 = 0%
another example :
actual = [1,0,1,1,0]
prediction = [1,1,0,0,1]
mse = 1/5 ( 0 + 1 + 1 + 1 + 1) = 4 / 5 = 0.8 * 100 = 80%
Tujuan utama dari MSE adalah metric error data prediksi kita berapa %. Dan dengan ini kita dapat meningkatkan performa dari algoritma kita agar error yang dihasilkan lebih kecil.
2. Recall Precision
Recall dan Precision merupakan sebuah metric untuk menentukan apakah hasil dari prediksi kita dibandingkan dengan data actual. Terdapat 4 kuadran klasifikasi hasil prediksi kita yaitu : True Positive, True Negative, False Positive dan False Negative

dari gambar diatas sudah cukup jelas bagaimana menentukan TP, TN, FP, FN.
contoh : actual = {1,0,0,1,1,1] prediksi = {1,0,1,0,0,0}
kita dapat mengkelompokkan menjadi TP = 1, TN = 1, FP = 0, FN = 3
Hal yang dapat kita lakukan dari metric ini pertama kali adalah menentukan accuracy. Untuk menentukan accuracy dapat menggunakan :

jadi akurasi dari prediksi kita adalah = (1+1) / (1 + 1 + 0 + 3) = 2 / 5 = 40 %
Untuk recall dan precision sendiri dapat menggunakan rumus dibawah ini :


dan recall untuk hasil prediksi kita adalah 1 / 4 = 25 % => 75% data yang yang harusnya direkomendasikan, tidak diberikan.
dan precision nya adalah 1 / 1 + 0 = 100 % => tidak ada data yang salah dalam rekomendasi kita
3. ROC Curve
Basically ROC curve adalah perbandingan antara True Positive Rate (Rate data yang diprediksi benar) dan False Positive Rate ( Rate data yang diprediksi salah). Jika melihat grafik :

kita dapat melihat sebuah garis putus — putus yang membagi 2 bagian. Bagian teratas menandakan jika ROC kita berada diatas garis putus-putus maka prediksi kita cukup baik dan jika ada dibawah garis putus-putus maka prediksi kita cukup buruk.
Contoh : Actual = {1,0,0,0,1,1,1} Prediction = {1,0,0,1,0,0,1} TP = 2, TN = 2, FP = 1, FN = 2
TPR = TP / (TP + FN) = 2 / (2 + 2) = 0.5
FPR = FP / (FP + TN) = 2 / 3 = 0.66
Jika kita lihat maka TPR = 0.5 && FPR > 0.5 maka kita dapat menyimpulkan jika titik ini akan dibawah garis putus-puts sehingga dapat kita simpulkan jika algoritma kita buruk.
Andrew Ng, dalam kuliah umum MOOC di coursera mengenai machine learning nya menyatakan, dalam menentukan algoritma gunakan dulu yang paling buruk. Karena yang terpenting dalam tahap awal adalah evaluasi metric mengenai algoritma kita. Dan yang jika menurut kita algoritma yang diberikan cukup buruk maka kita dapat mengganti algoritma yang akan kita tweak dengan algoritma yang lebih kompleks.
Donald Knuth said “premature optimization is the root of all evil” so don’t start with optimazation but start with define a metric, start with the worst and optimize it.


